最近几天,中文圈子里面最火爆的新闻,可能就是有关华为提出的韬定律,号称为国产芯片领域的"DeepSeek时刻",马上引起网络上的全面狂欢,让大家马上忘掉了煤矿事故那种事件。下面我们来具体分析一下,这个定律是什么,还有相关技术的历史发展。
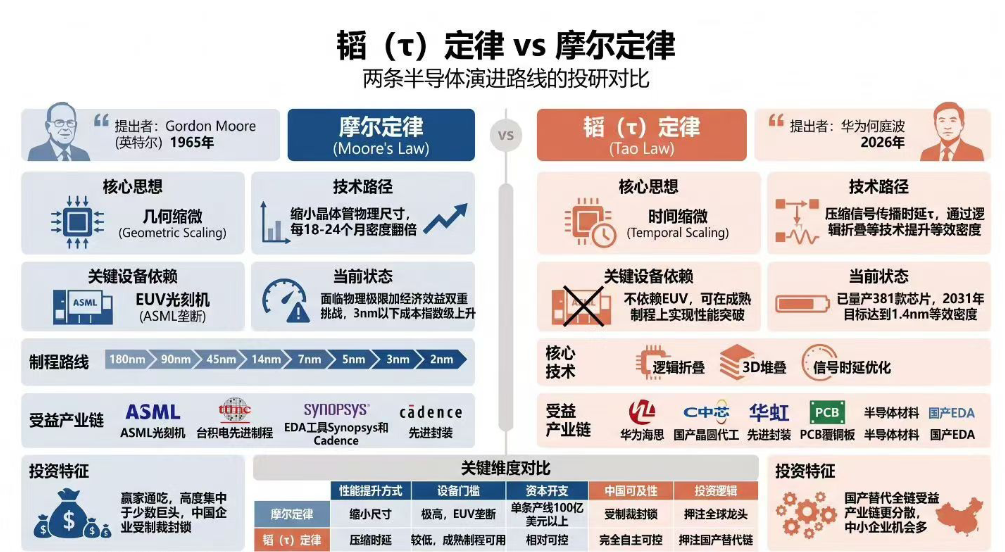
华为在2026年国际电路与系统大会(ISCAS 2026)上正式发布"τ缩放定律"(Tau Scaling Law,又称韬定律),提出以压缩时间常数τ取代晶体管几何微缩,作为芯片性能提升的新驱动范式,为国产半导体在不依赖EUV光刻机的前提下实现持续性能跃升,提供了一套完整的技术路线图。

τ定律的核心逻辑在于,将优化目标从晶体管物理面积转向信号延迟,通过在晶体管、电路、芯片、系统四个层级协同压缩时间常数τ,实现跨越摩尔定律约束的性能增长。伯恩斯坦指出,这一框架为中国半导体产业提供了可预期、可扩展的技术路线图,使其得以在EUV约束下持续迭代、逐步缩短与全球领先者的差距。
根据官方披露,华为通过名为"LogicFolding"的先进封装技术,已将晶体管密度从2025年的155百万/平方毫米提升至2026年的238百万/平方毫米(相当于台积电N3节点密度水平),并规划到2031年达到400+百万/平方毫米(相当于台积电14A节点密度水平)。在系统层面,华为目标在2030年前实现超级计算集群(superPoD)总算力125倍的提升,对应约每年3.3倍的复合增速。
可以说,这种理论几乎就是对于现在IC产业的变道超车。在没有EUV这种高端设备的前提下,算是一个新的技术路线和大胆技术赌注。

业内分析指出,逻辑折叠的折叠思路已经从封装层下沉到了电路布局层,并与器件优化、全栈软硬协同、系统互联总线形成四层级协同。换句话说,它比“先进封装”走得更深、更底层。问题不在“折叠”本身,而在于一个暧昧的关键词:等效。
华为提出的目标:到2031年,基于韬定律的高端芯片,晶体管密度达到等效1.4nm制程水平。这个“等效”二字,可以说是整个叙事中最精巧的设计,也是最危险的地方。
它是什么意思?在华为的语境下,它是指在特定场景、特定优化条件下,通过逻辑折叠和软硬协同,让芯片表现出来的单位面积性能和能效,接近于如果物理制程做到了1.4nm时可能达到的水平。这在工程技术上是合理的,也是华为过去六年在通信基站、AI芯片等领域反复验证的方法。
但问题在于,一旦“等效”这个概念从学术论文走向消费市场,它就极易被大众,甚至被投资者理解为“我们的14nm跟台积电的1.4nm一样了”。
半导体行业从来不缺“等效”的惨痛教训。三星当年为了“弯道超车”英特尔,在14nm时代把自己的工艺强行命名为10nm,在纸面上实现了反超。结果呢?Exynos猎户座芯片成了发热、降频的代名词,最终在Galaxy S系列中被全面封杀,三星手机业务不得不向高通低头。这个教训至今仍在业界回响:参数可以骗人,物理可以模糊,但功耗与能效不会骗人。
一个让很多人不舒服的事实是:所谓等效制程,从来就不是华为的首创。
台积电从16nm之后,每一代工艺的晶体管密度提升幅度都已远远跟不上节点数字的变化。所谓的“3nm”“2nm”,早就不是线宽的概念,而是根据晶体管密度反推出来的等效营销名称。整个行业都心照不宣地玩着这场数字游戏。
英特尔是唯一一个曾经坚持“按真实尺寸命名”的倔强老人,结果在市场宣传中被台积电、三星打得满地找牙。最终,英特尔也不得不放弃了物理真实,加入了数字通货膨胀的大军。
所以,当华为提出“韬定律”,用“时间缩微”替代“几何缩微”的时候,它在技术上做的,其实是整个行业都在做的事情,用架构、封装、软件来弥补制程的不足。但华为比所有人做得更成功的一件事,是为这件大家都在做的事,重新命名了一个定律。
想想看,摩尔定律是什么?它不是物理定律,而是一个产业观察、一个经验法则、一个商业叙事。英特尔用它统治了半导体产业半个世纪的话语权。现在,华为拿出“韬定律”,本质上是在做同样的事情:争夺半导体演进的定义权,建立以中国方案为核心的叙事体系。
绕开EUV光刻机,是每一个被封锁的半导体企业都在做梦的事情。韬定律能做到吗?一定程度上可以:通过更聪明的架构、更紧密的软硬协同,在14nm甚至更成熟的工艺上,做出接近先进制程的性能。这在通信基站、AI推理等功耗相对不敏感、软件可控的领域,已经被华为的381款芯片验证。
但在智能手机这样的终端上呢?低功耗、小体积、高集成度,这些是消费电子的铁律。逻辑折叠带来的3D堆叠,天然会带来散热和供电的挑战。折叠之后的信号串扰、时钟同步、测试良率,每一项都是硬骨头。华为说秋季即将发布的麒麟芯片将首次完整采用这套技术,晶体管密度提升55%,功耗效率提升41%,主频回到3.1GHz,这是令人期待的数字,但不是最终答案。
真正的答案在消费者拿到手机、安装游戏、连续刷两个小时视频之后的手温里。在那些不需要打开跑分软件、不需要看参数表格的日常瞬间里。苹果曾经教会我们一件事:忘掉数据,感受流畅。那是乔布斯从禅宗里悟出来的“不立文字”的境界,不是现在的苹果。而华为现在的做法,恰恰是反过来的:用一套宏大的文字,试图重新定义数据,从而定义体验。
这种做法在当下的产业焦虑中无比正确,因为它给了资本市场一个巨大的信心支撑。但我们不能因此就忘记了:终端的体感,才是最终的评价标准。
当韬定律横空出世的时候,整个消费电子行业几乎是扑上去拥抱这个叙事的,因为太需要了,太需要一个让人相信“芯片还在进步”“手机还能更牛”的故事了。没有故事,怎么卖货?怎么撑起万亿市值的想象空间?
但作为用户,作为消费者,作为那个最终掏钱买单的人,我们必须问自己一个问题:手机用上那颗逻辑折叠后的芯片,在我不跑AI大模型、不打原神、只是刷抖音和聊微信的时候,我能感觉到它和台积电3nm芯片有明显区别吗?
答案很可能是:不能。
这不是华为的问题,这是整个行业的瓶颈。当芯片性能早已超过90%用户的日常需求时,再往上堆性能,边际体验趋近于零。唯一的出路,不是继续在参数上内卷,而是找到真正能改变人机交互、改变生活方式的新形态,可能是AR,可能是脑机接口,更可能是某种今天完全想象不到的东西。
那有关的技术是否是华为首创,或者第一次出现,那就更加不是了,我们可以来回顾一下3D芯片的历史。
关于3D IC的历史事实:电气工程师其实已经在第三维度里思考和工作了七十余年。
纵观过去,无论是早期实验室的手工模块,还是现代微电子的精密堆叠,人们不断试图在空间中寻找新的可能。
三维,不仅是物理的高度,更是一种思考方式——将复杂问题分层、交织与整合,用垂直的视角突破传统的限制。
然而,当我们回望这一百年的探索,不禁要问:
到底是因为先进所以选择 3D,还是因为 3D 才孕育出先进?
或者,它们之间,根本没有必然的联系。
如果假设成立,那么3D IC何以先进?
1953 年,美国海军航空局资助了一个名为 Project Tinkertoy 的研究项目,其目标不是追求更高的频率,也不是微米级的晶体管,而是彻底革新电子系统的生产方式与模块化思维。

当时的电子产品——无论是军事设备还是早期计算机——几乎都是靠技师用手工点对点焊接连接元件,这种“线到哪儿算哪儿”的方法,在二战后和朝鲜战争期间暴露出严重的瓶颈:熟练焊工短缺、生产成本高、交货期长。Tinkertoy 试图打破这一局面,它提出了一种基于标准化 陶瓷晶圆(约 7/8 英寸见方) 的模块化体系。每块晶圆上用丝网印刷技术预先形成导线图案,并通过机械化设备把电阻、电容、线圈等元件自动装配上去;然后将这些晶圆 垂直堆叠,通过外围的连接线既作为支撑结构又实现电气互联,最后堆叠成一个完整的电路模块。
这些模块不仅具备了当时技术条件下难得的紧凑与标准化,还能组合成更大功能单元,例如用于声纳浮标或无线电高度测量设备的系统。Tinkertoy 的试点生产线甚至能够每小时制造数百块晶圆和模块,生产效率据说比传统手工装配提高显著、成本降低约 44%。
那么大家可能会问:“为什么不直接用印刷电路板(PCB)?”
一个简单却尖锐的回答是:那时 PCB 还没真正普及成为主流工艺。
当然,更深层的现实是——那时的电子技术仍处在转型前夜:晶体管才问世 5–6 年,制造工艺更像是炼金术而非现代材料科学,集成电路自然还未出现。
所以,3D 在电子工业真正成为趋势之前很久,它其实已经存在了——只是那时没有人能准确预测它未来的角色。
第一个真正意义上的集成电路,本身其实也是一个三维结构的装置。时间回到 1958 年 9 月 12 日,当时在德州仪器(Texas Instruments)工作的工程师 Jack S. Kilby 造出了世界上第一块集成电路原型。他的设计与后来我们熟悉的平面 CMOS 或硅片芯片截然不同:Kilby 用一小块 锗(germanium) 硬质材料作为基底,上面集成了一个晶体管、一个电容和几个电阻等基本元件,通过手工焊接的细金丝实现彼此之间的电气连接 —— 可以说,是在一个小小的立体空间里把多个功能部件实际“装进去”。这个原型尺寸只有约 1.6 mm × 11 mm,但它真正证明了“把所有电子元件和连线集中在一块固体半导体材料上”的可行性。
时间来到辉煌灿烂的电子70年代。在1979年出现的 Mostek MK38P70 微控制器,就是一个典型的例子,说明即便 IC 已经商业化并开始风靡,三维集成在真正被认可为“先进技术”之前,其实依然是被当作临时权宜之计来使用的。

相比后来在芯片内部集成可编程存储器(如 EEPROM、Flash)以及平面化封装技术——包括后来广泛采用的塑封 DIP、QFP、BGA 等——这种“堆叠式”封装看起来反而像是用 70 年代的思维去应对 70 年代的问题。
IC 虽然在市场上已经大规模商用且高速发展,但所谓的“3D 集成”仍未真正成为主流路线。
它更多是解决当时技术局限的权宜之计,而不是我们今天理解的那种先进制造技术。
在 DRAM 的演进史里,1985 年的一个小插曲同样说明了那个时代三维组装的“原始魅力”。
当时制造商手里的主流水平仍是容量为 64 Kbit 的 DRAM,可市场上对更大容量的需求与日俱增——尤其是在个人电脑领域,诸如 IBM PC/AT 克隆机这种需要突破“640 K 内存门槛”的系统上,内存容量与电路板空间之间的矛盾愈发尖锐。
在这背景下,德州仪器工厂的一组设计人员想出了一个看似“笨拙但有效”的办法:
将两颗 64 Kbit 的 DIP(双列直插封装)DRAM 堆叠起来,然后在封装之间直接焊接互连,形成一个紧凑的 128 Kbit 单元。
在经历了 70 和 80 年代各种“封装对封装”、“封装堆叠”的权宜之计之后,到了 90 年代初,真正有一些工程师开始试图把三维集成推向更严肃的技术路线——不仅仅是为了节省 PCB 空间,而是为了在更高层次上提高内存密度和性能。一个典型例子来自 Irvine Sensors Corporation(ISC)。
Irvine Sensors 在 1990 年代初 受 NASA 和美国国防部合同 的资助,开始开发一种名为 “Memory Short Stack” 的三维内存系统,这是一种真正意义上把多片 DRAM 或其他存储器芯片 垂直堆叠成小立方体式封装 的技术。
不同于前面我们讨论的那些只是把封装叠在一起的经验做法,这种 “short stack” 通过专利的芯片堆叠方法将数十片芯片垂直排列,形成一个小立方体,在更紧凑空间内实现更高的集成度、更短的连线、更低的功耗。这些堆叠单元据说甚至可以在约一立方厘米的空间内容纳四到十多个内存芯片,达到最高数十兆比特的总容量。
这种被称为 “cubing”(立方堆叠) 的技术不仅是为 NASA 的航天、空间飞行器和高密度数据记录设备开发的,还因其高密度、多芯片一体化的潜力吸引了商业大厂的注意。
1992 年,Irvine Sensors 与 IBM 签署了一项联合开发与制造协议,IBM 授权并计划利用这项技术生产堆叠内存器件,并希望将之推向更高的产量和更广的应用领域。
在当时的技术语境里,这种 Memory Short Stack 有两个显著特点:
- “真正”意义上的 3D 堆叠结构——芯片不是简单贴在顶部,而是按高度方向组织在一个紧凑体积中,信号路径更短、集成度更高;
- 技术目标超越简单封装优化——它试图通过三维集成减少功耗、提高速度、提升整体存储带宽,这在当时对航空航天和高性能计算系统尤其重要。
当然,Memory Short Stack 并未像后来平面集成度爆发那样成为主流存储器形态,但它确实是 3D 思路在存储集成领域中一个更早、更系统化、更接近“真正三维 IC”的尝试。
作为 1990 年代初少数几条跨越封装与芯片堆叠边界的技术路线之一,它为后来 3D-IC、3D 堆叠存储、立体互联(如 TSV、焊球立柱等技术)预演了许多关键思考。
进入21世纪,3D IC的历史开始与人们认知中的先进技术演进历史逐步重合
真正进入 21 世纪之后,三维集成终于等来了一个不再只是“能用”,而是在系统层面不可替代的应用场景。
一个标志性的例子,来自美光(Micron)主导的 Hybrid Memory Cube(HMC,混合内存立方体)。
HMC 的核心目标非常明确:在更小的形态和更低功耗下,提供远高于传统 DRAM 的带宽。为此,它系统性地采用了 贯穿硅孔(Through-Silicon Via, TSV) 技术,将多层 DRAM 芯片垂直堆叠,并在堆栈底部集成了一颗专用的逻辑芯片,用于内存调度与接口管理。

这一设计之所以成立,恰恰源于一个长期被忽视、却在 21 世纪被重新正视的事实:
几乎所有现代 SDRAM,本质上都是由多个低速 DRAM 阵列组成的。
这些阵列的内部工作频率通常只有 200–400 MHz,但为了满足系统带宽需求,它们被迫通过诸如 DDR3 这样的高速、但相对狭窄的外部接口进行时分复用和数据引导。问题在于,这种做法把能耗、复杂度和信号完整性的压力,全部集中在接口上。
HMC 的思路正好反其道而行之。
通过 TSV 带来的极高垂直互连密度,位于堆栈底部的逻辑芯片可以同时、并行地访问多个 DRAM 银行和通道,而不再依赖单一的高速接口去“轮询”这些阵列。结果是:
- 总带宽大幅提升,但单通道的工作频率可以显著降低;
- 接口功耗明显下降,因为能耗与频率和信号摆幅强相关;
- DRAM 不再只是“被动存储”,而成为一个高度并行、由逻辑层统一调度的立体系统。
也正因如此,堆叠内存在 21 世纪成为 3D 集成电路组装中少数真正称得上杀手级应用(killer application)的方向之一——不是因为它看起来先进,而是因为在那个性能—功耗—形态三重约束同时收紧的时代,它几乎是唯一可行的解法。
2014 年:SK 海力士 HBM,3D 堆叠内存走向成熟
到了 2014 年,3D 内存的概念终于在工业界迎来了真正的成熟应用。SK 海力士发布了其首款 高带宽内存(HBM, High Bandwidth Memory) 产品,标志着垂直堆叠 DRAM 从实验室或小规模原型,迈入可量产的工业化阶段。

从历史角度看,HBM 的推出不仅仅是一个产品发布事件,而是3D 堆叠内存技术商业化的里程碑。它完成了从早期 PoP、封装对封装到真正基于芯片级 TSV 堆叠的技术演进,同时也为未来多层 HBM(如 HBM2、HBM2E、HBM3)和 AI 加速器内存架构奠定了标准。
2015 年:AMD Radeon™ Fury,GPU 首次集成 HBM
HBM 在 2014 年量产问世后,仅仅一年,3D 内存技术就迈出了向高性能图形处理器整合的关键一步。2015 年 7 月,AMD 发布 Radeon™ Fury 显卡,它成为 第一款将 HBM 通过 TSV 和微凸点与 GPU 整合在一起的图形处理器。
其封装结构基于 2.5D 封装理念:一颗大型 GPU 裸片与四颗 HBM 堆栈并排放置在同一个 硅互连载板(Silicon Interposer) 上,通过微凸点和 TSV 实现高速垂直互连。虽然 GPU 与 HBM 本质上仍然是“平行放置”,但通过硅互连,逻辑芯片可以同时访问多颗 HBM 堆栈,从而形成高密度、高并行的数据通路。

2016 年:Xperi DBI 混合键合实现量产——索尼 IMX260 的应用
2016 年:台积电 CoWoS 大规模量产
2019 年:英特尔 Foveros,实现“主动互连板”堆叠
3D 只是一个舞台,而每一次跨越——无论是 TSV 的贯穿、微凸点的精细化、硅互连中介层、DBI 混合键合,还是异构芯片的垂直整合——才是推动性能、功耗、带宽、尺寸突破的真正力量。
當然,华为韬(tau )定律的核心涉及3D芯片技术,但它不仅限于物理层面的3D堆叠与先进封装,而是一套更底层的、贯穿全产业链的系统性创新体系。
包括底层突破“逻辑折叠”技术,全栈协同优化,高密度先进封装与检测,简单来说,“韬定律”旨在打破“摩尔定律”单纯依赖物理线宽缩小的限制,通过3D架构折叠+系统级软硬协同,让中国半导体产业在先进制程受限的条件下,能够走出一条独立自主的演进路线。
老实说,华为提出的韬(tau )定律,既不是历史第一次,也不是没有人尝试过,不同的没有哪个公司作为一个定律提出来。但是的确可以成为EUV这种设备被限制下的一种新的思路,关键是华为有着自己的芯片设计和部分生产技术,它可以用自己的生态进行验证,进行优化,未来还有有很大的发展前途,也有可能成为和现在的IC技术成为竞争的另外一种技术系统。
有竞争从来都是好事情,未来会如何,大概率到了2031年,我们可以来回顾一下,让我们拭目以待吧。
(本文內容大量來自於網絡)